João Thomas S. Telles | Time Wall-E - 14/11/2022
¶ O que você precisa saber para entender este estudo:
¶ Introdução
Você pode já ter ouvido falar de Sharding, uma técnica relativamente comum em bases de dados não relacionais, que permite que uma mesma tabela seja repartida em várias instâncias de um SGBD.
Também existe a ideia de Particionamento de tabelas, nativa do SQL Server.
A ideia da fragmentação de bases veio de uma hipótese um pouco mais antiga, onde estavamos pensando em repartir uma base relativamente grande em outras 2 bases, seguindo a lógica de quente e frio.
Como a base era muito grande, e nenhum pouco particionada a nível de tabelas, a quantidade de cores de processador necessários para fazê-la rodar é extremamente alta, e esse estudo é fundado na ideia de fazer com que ela base necessite de menos processamento para se manter.
¶ Estudo Inicial
A hipótese inicial era separar as tabelas da base grande em tabelas com o sufixo -hot, e -cold, de modo que no lugar de uma tabela só, existiriam duas tabelas, e para fazer consultas seria criada uma view, que iria servir de interface para as outras duas tabelas.
Exemplificando com uma tabela chamada Pessoa: Originalmente você teria somente a tabela Pessoa, porém após as alterações você teria uma View Pessoa, uma tabela Pessoa-hot, e outra tabela Pessoa-cold. A separação dos dados seria de acordo com a Lei de Pareto - 20% dos dados são os que são mais acessados dentre todos os outros, como pode ser visto na Figura 1.
Figura 1 - Fonte:(https://asana.com/pt/resources/pareto-principle-80-20-rule)
Para fazer os inserts, updates e afins, teriam-se triggers, que iriam inserir na tabela quente,ou alterar onde fosse necessário. No teste inicial, feito com uma tabela só, parecia funcionar plenamente! Então, esperançosamente, fui ao próximo teste: testar em uma copia da base grande citada anteriormente. De cara, já foi encontrado um grande desafio: como migrar as tabelas sendo que elas estavam presas por constraints de foreign key?
Bom, aquela era a parte fácil; após conseguir quebrar as tabelas, foi-se deparado com outro problema: após migrar as tabelas, como garantir a integridade dos relacionamentos? Por que se eu migro a tabela Pessoa, a tabela Endereco que era associada a ela perde o relacionamento à tabela Pessoa, que agora é uma view. Como não é possível colocar constraints em uma view, poderia ser feito uma trigger para validar os constraints.
Se essa ideia desse certo, poderia ser feito a separação da base em dois servidores diferentes, o que tornaria possível licenciar a base grande. Porém, como foi notado anteriormente, seria necessário fazer triggers para todo o funcionamento de todas as tabelas. Fundamentalmente, seriam necessárias 3 triggers por tabela de aproximadamente 20 linhas cada, para garantir que nenhum relacionamento fosse quebrado.
Após ter essa percepção, decidi buscar se era viável fazer sharding em SQL Server, e foi nessa pergunta do Stack Overflow que eu descobri que não. Porém na resposta presente no artigo, são apresentadas as alternativas de Table Partitioning e Partitioned Views.
Resumidamente, a ideia de particionar uma tabela em quente e frio e usar uma view para representar as duas tabelas seria um bom exemplo de partitioned views, como também um bom exemplo da fraqueza de uma partitioned view : não tem como vincular foreign key com uma delas. A implementação de uma Partitioned View pode ser viável em cenários onde a tabela não é dependêcia de nenhuma outra, porém em qualquer cenário em que há dependência, o particionamento com views se torna inviável.
¶ Introdução ao Conceito de Particionamento de Tabelas em SQL Server
Você particiona uma tabela no SQL Server por muitos motivos… muito espaço ocupado em um disco só, problemas de performance e etc. Mas o que é particionamento de tabelas?
Em um banco de SQL Server padrão, as tabelas e o banco em si estão salvos no mesmo grupo de arquivos, que pode ou não estar espalhado em vários discos. Quando você vai fazer um select, é como se o SQL perguntasse ao(s) arquivo(s): Onde está a linha X? E no cenário onde só há um grupo de arquivos, ele precisa percorrer a maioria dos dados até encontrar a linha X. Em termos de performance, é um O(Log (n)) em uma tabela com indices no pior cenário, conforme esta resposta.
Ao particionar uma tabela em SQL Server, você deve especificar o filtro que irá dividir as partições, como por exemplo, 12 partições uma para cada mês, ou alguma divisão baseada na Lei de Pareto. E isso muda a forma com a qual o SQL faz a pergunta. Ao invés de perguntar: Onde está a linha X? E depois ter que percorrer grande parte dos arquivos, já de início ele tem uma resposta: A linha X está na partição Z, por exemplo. Em termos de um select que cabe dentro de uma mesma partição, a perfomance, comparada ao cenário inicial é de O(Log(n)/Z), onde Z é a quantidade de partições. Na Figura 2, pode ser observado os gráficos das diversas notações BIG - O
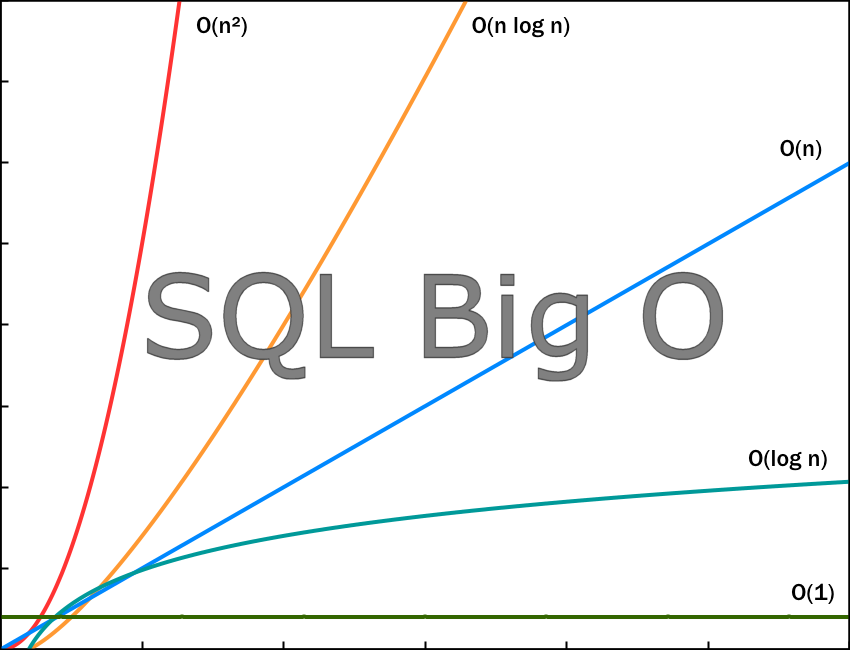
Figura 2 - Fonte:(https://blog.devgenius.io/estimate-time-complexity-of-java-and-sql-query-afa13a88a981)
Dessa forma, o particionamento de tabelas se demonstra uma solução extremamente performática em tabelas com uma grande quantidade de valores, como é o cenário atual que o Time Wall-E trabalha.
¶ Como particionar uma tabela?
O SSMS(SQL Server Management Studio) prove uma maneira bem fácil e interativa de como particionar uma tabela, mostrando até simulações de quê tamanho ficariam as tabelas. Basta selecionar a tabela que você quer particionar, clicar em Armazenamento, e em particionar.
Caso você ainda tenha dúvidas, veja como particionar tabelas neste tutorial aqui.
¶ Conclusão
Conforme exposto nos outros tópicos, a fragmentação de bases SQL Server pode ser feita tanto com Partitioned Views, quanto com Particionamento de Tabelas. Tendo em vista limitações de licenciamento, este estudo preferiu focar nas ideias de performance que um Particionamento de Tabelas poderia prover.
Ao particionar uma tabela, você consegue melhorar a performance de uma base grande exponencialmente, basta seguir um particionamento adequado. Neste estudo foi detalhado o por quê de utilizar o particionamento de tabelas, além de um leve como. O próximo estudo será detalhando as melhores práticas de particionamento de tabelas que o Time Wall-E encontrou.